Background
- Why 2 FEs?
Microsoft has clearly said that 2 FE topology is supported, but not recommended. Then why I still chose to deploy such a topology? In a word, the decision-maker made this choice. More considerations, a 3rd FE costs another Lync Server license and more resource, yet Microsoft hasn’t clearly mentioned that it could cause the following unexpected issue.
- System Topology

Details:
Lync Server 2013
Enterprise Edition Pool, FE * 2
BE mirroring, BE01 as Principal, BE02 as Mirroring
Virtual machines on 2 physical hosts
- HA considerations
Service can continue if any single server downs (FE or BE)
Service can continue if any single physical host downs (#1 or #2)
Issue
When testing HA, the following issue occurs:
(Single-server-failure test passed in any case, and physical-host #2-failure test passed as well)
If one FE and the Principal BE fail, even if you fail over BE to Mirroring BE a.s.a.p., the other FE’s Front End Service will stop in several minutes.
And these key events showed in event log:
#32163: Local Pool Manager has been disconnected from Pool Fabric Manager.
#32170: Pool Manager failed to connect to Fabric Pool Manager
#32173: Server is being shutdown because fabric pool manager could not be initialized
More Information
hose events look familiar? Yes, just as described here,
http://technet.microsoft.com/en-us/library/gg412996.aspx , “If the number of servers running falls below the functional level as shown in this table, the remaining servers in the pool go into survivability mode, and…”
BUT, for a 2-FE pool, Number of servers that must be running for pool to be functional is 1, which means even if 1 server downs, the rest one should continue serving without issue. It doesn’t mention that BE should also be up as well. Even if there is “something” to do with BE, it can be failed over very soon, there should be no problem.
AND, since all there events (32163, 32170, and 32173) are related to Fabric service, I checked Windows Fabric event logs and found this event, saying Windows Fabric cannot connect a database called rtcshared. It is a database located in BE.

*the Japanese part means “Cannot open database ‘rtcshared’ requested by the login. The login failed.”
In database rtcshared, there’s a table dbo.WinFabricVote attracted my attention, which has three records, as the image below:

A Little Review
Words back to Lync Server 2013’s new Architecture: the Brick Model. Some new concepts are introduced to help improve Lync’s High Availability, User Groups, Windows Fabric, etc. Refer these articles for detailed information.
http://windowsitpro.com/lync/lync-server-2013-windows-fabric-user-groups
http://windowsitpro.com/lync/lync-server-2013-brick-model
Assumption of the Quorum Formula
We know that for Front End Servers to keep serving even if one or more FEs go down, there is a must that number of running FEs must be greater than a number called quorum. How is quorum calculated?
Quorum = ⌊ (n + 1) / 2 ⌋
*n is number of Front Ends in the pool, and “⌊ x ⌋” means to calcite the largest integer not greater than x.
This formula is almost perfect, except when there are only 2 FEs in a pool. For Windows Fabric to work there should be odd-numbered nodes. A node can be a server or something else. Every node has the right to vote. When the total number of votes exceeds half of the number of nodes (>50%), servers are approved to keep running; else all of them have to go down. If there are even-numbered nodes, there is a possibility that the vote result is just 50%, Fabric will be confused to make decision. Usually these nodes are Front Ends, but when the number comes into 2, a 3rd node will be created. In Lync case, the 3rd one is BE.
So here n is 3, not 2. And for Lync to continue serving, there should be at least ⌊ (3+1)/2⌋=2 nodes working, like 1 FE + 1 FE, or 1 FE + 1 BE. When two nodes stop, if you can’t bring one more node back in about 5 minutes, the rest FE will go into survivability mode and then stop its Front End Service.
Prove My Assumption
To prove my assumption, I finally found an evidence at C:\Program Files\Windows Fabric\bin. This is where Windows Fabric is installed. ClusterManifest.current.xml is the Manifest file current in use. The Votes section defines nodes that have the right to vote.

Clearly we can see, there are 3 nodes that can vote, FE, FE2, and BE’s rtcshared database.
FYI: The table dbo.WinFabricVote mentioned above is also created by Windows Fabric. In bin\Fabric\Fabric.Code.1.0, you will find WinFabricCreateVoteTable.sql.
~~~~~~~~~~~~~~~~~~
— PLEASE SET VARIABLES “DATABASE” AND “SCHEMA”
USE $(DATABASE)
IF NOT EXISTS (SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = ‘WinFabricVote‘)
CREATE TABLE $(SCHEMA).[WinFabricVote] ([Type] NVARCHAR(100) NOT NULL, [Key] NVARCHAR(100) NOT NULL, [Version] BIGINT NOT NULL, [Data] VARBINARY(8000), PRIMARY KEY([Type], [Key]))
INSERT INTO $(SCHEMA).[WinFabricVote]
VALUES (‘Arbitration’, ‘Lock’, 0, 0)
~~~~~~~~~~~~~~~~~~
Another Question
Here comes another question. As the Votes section defined,
~~~~~~~~~~
<Parameter Name=”SQL” Value=”SqlServer,Driver=SQL Server;Server=SQL1.***.***\LYNCDB;Failover_Partner=SQL2.***.***\LYNCDB;Database=rtcshared;Trusted_Connection=yes”/>
~~~~~~~~~~
From the definiation we can assume that, when the principle BE goes down, Windows Fabric should try to connect to its failover partner. And if BE is correctly failed over, the connection should result in success, and then the event 21249 should not happen.
Why this happens?(Assumption)
After several experiments(progress omitted here), I found that the connection string Windows Fabric uses when connect to database is strange.
the description of event 21249 metioned
~~~~~~~~~~
…
Message = [Microsoft][ODBC SQL Server Driver][SQL Server]…
…
~~~~~~~~~~
It’s using ODBC and SQL Server Driver to connect to target database. What’s its connection string? It’s in Fabric’s Manifest file.(red bold string)
~~~~~~~~~~
<Parameter Name=”SQL” Value=”SqlServer,Driver=SQL Server;Server=SQL1.***.***\LYNCDB;Failover_Partner=SQL2.***.***\LYNCDB;Database=rtcshared;Trusted_Connection=yes”/>
~~~~~~~~~~
Using SQL Server Driver will never have ODBC connect Failover Partner. The right Driver is “SQL Server Native Client 11.0“.
Prove My Assumption (again)
To prove my assumption (again), we should modify Windows Fabric Manifest file and have it loaded and worked.
I tried a lot and found FabricDeployer.exe meets my needs.
It’s located in C:\Program Files\Windows Fabric\bin\Fabric\Fabric.Code.1.0
Run it in Command Prompt to update current manifest.
~~~~~~~~~~
FabricDeployer.exe /operation:update /cm:”ClusterManifest.xml”
~~~~~~~~~~
*Don’t forget to backup current manifest file in case of happenings.
Then, go the HA test again.
Test Step
1. FE01, FE02, BE01 (Principal), BE02 (Mirroring) all online
2. Simulate FE01 and BE01 fails (disable their NICs)
3. Fail over BE to BE02
4. Watch
Results
- FE01: Lost connection to Fabric Manager, Front End Service stops automatically after several minutes (EXPECTED result)
- BE01: Lost connection to network, Mirroring BE (BE02), and FEs (EXPECTED result)
- BE02: Lost connection to BE01. Became Principle BE after failing over (EXPECTED result)
- FE02:
Lync Server Event Log:
#32163 occurred several times
#32162 “Local Pool Manager has connected to Pool Fabric Manager” occurred after 32163 (evidence that 32163 error is solved)
#32170,#32173 didn’t occure
Windows Fabric Event Log:
Following 2 events show that connection is established succesfully after modifying Fabric Manifest
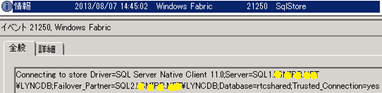

After BE01 went down, failed over to BE02. At first connection lost event occured.

It was trying to connect to rtcshared using driver “SQL Server Native Cient 11.0”

Failed in about 15s.
This is by design, http://msdn.microsoft.com/en-us/library/ms175484.aspx

During the period of trying connecting to rtcshared, Fabric Node failed

After several cycles of tries, finally connection was established successfully.

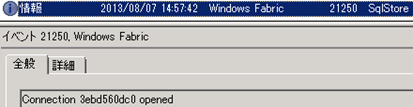
Notice that the connection ID “3ebd560dc0” is different from the one before “f4931f0ea0”, which shows that a new connection is established.
At last Fabric Node was open again.

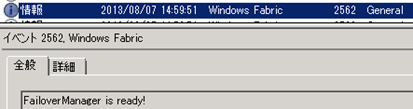
Conclusion
- my assumption that the conenction string used by Windows Fabric is wrong has been proved.
- 2FE + 2BE HA topology should work
The Story Has Not Over Yet
Finally reached the main target. But, there’re still 2 problems that I cannot figure now
- FE01’s Fabric Manifest rolled back automatically
During the test, FE01’s Front End Service stopped as expected. But, after about 30 minutes that Windows Fabric detected fails, FabricDeployer.exe started automatically and loaded manifest again. During this progress, manifest was reset to its original content! (“Driver=SQL Server Native Client 11.0” was rolled back to “Driver=SQL Server”) Is this hard-coded? - FE02’s Windows Fabric went into quorum loss state
After Windows Fabric succesfully connected to Mirroring BE, the following event kept coming out every 5 seconds. It didn’t stop even if you bring FE01 back, or fail BE back to BE01.

Managed to stop it by reset pool’s state,
Rest-CsPoolRegistrarState -ResetType FullReset -PoolFqdn <pool FQDN>
But, with Fabric service restart, Manifest was reset to original content as well
Notice
Please do not do the same test in product environment, or do it under self responsibilities.

Thank you for great post! I could understand well how Windows Fabric worked.
By the way, I found “Votes” section in “C:\ProgramData\Windows Fabric\Settings.Xml” but not in “C:\Program Files\Windows Fabric\bin\ClusterManifest.current.xml”. This is just a report because it might be specific to my lab environment.
Thank you for feedback! I’ll look further into it.
thanks,
so have this ever been fixed where you have 2 frontends and be fails and mirror has the rtcshared database?